
The research paper for this article can be downloaded from the following link: https://bit.ly/MvTAe
The complete code can be found at the following GitHub repository: https://github.com/jaungiers/MvTAe-Multivariate-Temporal-Autoencoder
Introduction
Temporal sequence prediction problems have been studied for centuries using ever more complex methods with the aim of capturing hidden patterns within and predicting those patterns going forward. Any temporal process has drivers which determine its behavior; in theory any and all of these drivers can be modelled given enough data about that process at a point in time and a complex enough model — in practice however this is currently unfeasible for a variety of reasons, the main of which are capturing the data, computing the captured dimensionality of the data and modelling the complex interaction of many dimensions interacting in various correlated ways.
An example of the complexity of such a problem might be the seemingly stochastic path of a raindrop down a window. By all respects this raindrop would appear to be taking a random walk down the windowpane, with the left and right movements seemingly unable to be determined or modelled. Consider however having the position of every water molecule, every glass molecule, their respective temperatures and their historical interactions graph with every other molecule available as data at every granular point in time. Given this information, it is reasonable to assume that there exists a model which can be created that is accurately able to specify where the raindrop will go next, and by extrapolating, where it will end up when it reaches the bottom of the windowpane.
The problem of course with the above example is that there currently exists no such method of capturing every observable aspect of a universe at a point in time. Hence for now the best we can do is look to create a model to approximate the hidden drivers of the raindrop given the best data we can gather.
Whilst this isn't optimal for the example raindrop problem, the good news is that there are ample problems where a large amount of data can be gathered at very fine points in time and hence a model can be created to forecast the problem process.
Processes which have a small, closed universe of potential drivers that influence their behavior are easier to forecast for greater sequential steps ahead, whereas processes which are exposed to a great variety of influencing drivers succumb to the exponential decay of accuracy through chaos and as such are only able to be modelled very short sequential steps ahead. The more influencing drivers of a system can be worked into the model however, the more accurate the prediction process will be going forward.
This research focuses on building a model which can process multivariate temporal sequences of data, which in real-world data problems act as the influencing drivers of a process and which learns to build a hyperdimensional approximate representation of the drivers and process in an unsupervised manner. This trained hyperdimensional hidden representation then acts to train a secondary predictive model branch to forecast sequential steps ahead. The model is created using a multi-branch deep neural network approach utilizing the autoencoding principle and building on a sequence to sequence approach created by Sutskever et al. for creating the hyperdimensional hidden state representation. The model is henceforth referred to as Multivariate Temporal Autoencoder (MvTAe).
The dataset used in this research is created to be of a toy-dataset nature used to demonstrate the MvTAe model in simple yet fully functional circumstances. This research is not concerned with the other major challenge of real-world usage concerning observation, measurement and data processing.
Synthetic Multivariate Temporal Dataset
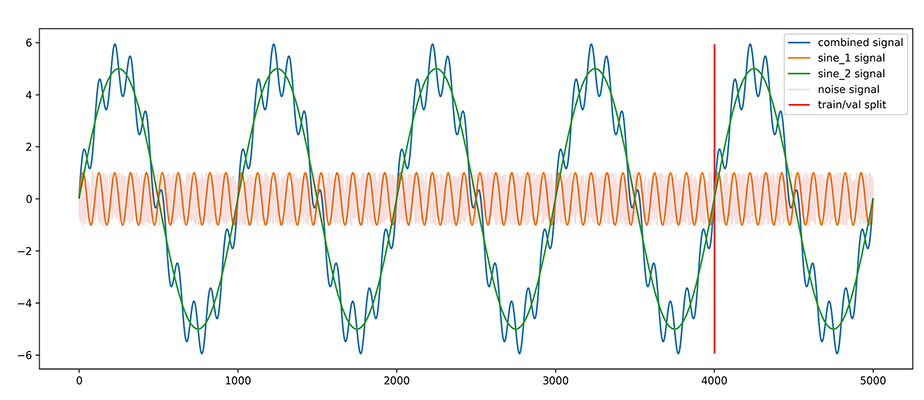
To train and test our multivariate temporal autoencoder model we create a synthetic toy-dataset which contains several specific dimensions:
- sine_1: a sinusoidal wave with a cycle period of 100 timesteps and an amplitude of 1.
- sine_2: a sinusoidal wave with a cycle period of 1000 timesteps and an amplitude of 5.
- noise: a gaussian distribution of stochastic noise between -1 and +1.
- combined_signal: a sum of sine_1 and sine_2. This will be used as the Y target variable we are looking to predict and will NOT be included in the X training data that the autoencoder branch of MvTAe sees.
The dataset is created in this way as to provide a way to test our autoencoder model for several important attributes. The first sinusoidal wave is a repeating pattern over time which will test the ability of our model to capture the sequential process of this pattern. The second sinusoidal wave creates a longer term cyclical sequence pattern which our model will not be able to see in full for each training example and hence it tests the model's ability to capture cyclical trends. The noise dimension adds an extra dimension of redundant information to test the model's ability to identify and disregard dimensions which do not contribute to the latent drivers of the data. Finally, the combined signal will test the ability of the predictive branch of MvTAe to combine signals from the two visible dimensions into this third hidden target dimension.
In the autoencoder branch of the model this combined signal dimension is not used as input, since in this stage the aim is to create a latent vector representation of the visible X dimensions of the dataset. In the second-stage predictive branch the combined signal is used as the Y target for future predictions.
To feed our model, the dataset is split into sliding windows of length N with step S between each window. This approach allows the training of our autoencoder branch to lookback across N temporal steps to determine relationship patterns within the temporal sequence. The Y targets of our first-stage autoencoder branch are the inverse of our inputs along the temporal axis. The Y targets of our second-stage predictive branch will be the ti+1 combined_signal dimension for each window of t(i-N) → ti.
The code for creating the normalized sliding windows across dimensions and the accompanying target variable is below:
idx_front = 0
idx_rear = window_size
features_x = ['sine_1', 'sine_2', 'noise']
feature_y = 'combined'
tr_data_windows_size = int(np.ceil((data['sine_1'][:idx_val_split].shape[0]-window_size-1)/step_size))
tr_data_windows = np.empty((tr_data_windows_size, len(features_x), window_size))
tr_data_windows_y = np.zeros(tr_data_windows_size)
i = 0
pbar = tqdm(total=tr_data_windows_size-1, initial=i)
while idx_rear + 1 < data['sine_1'][:idx_val_split].shape[0]:
# create x data windows
for j, feature in enumerate(features_x):
_data_window, _hi, _lo = norm(data[feature][idx_front:idx_rear])
tr_data_windows[i][j] = _data_window
# create y along same normalized scale
_, hi, lo = norm(data[feature_y][idx_front:idx_rear])
_y = norm(data[feature_y][idx_rear], hi, lo)[0]
tr_data_windows_y[i] = _y
idx_front = idx_front + step_size
idx_rear = idx_front + window_size
i += 1
pbar.update(1)
pbar.close()
# reshape input into [samples, timesteps, features]
tr_data_size = tr_data_windows.shape[0]
tr_input_seq = tr_data_windows.swapaxes(1,2)Eqn. 1 — Normalization:
Wnormalized = ( Wk(i-N)→i − min(Wk(i-N)→i) ) / ( max(Wk(i-N)→i) − min(Wk(i-N)→i) )
As is standard practice when training deep neural networks for optimal converging performance, we normalize our data. As we are dealing with temporal data windows along multiple dimensions, we treat each window and each dimension within the window as independent in terms of normalization. What this means is that for each window W of dimension k we normalize the data independently of all other k dimensions within that window. For the normalization process itself we use standard MinMax Normalization. As such, the normalization process can be summed up as per Eqn. 1.
def norm(data, hi=None, lo=None):
hi = np.max(data) if not hi else hi
lo = np.min(data) if not lo else lo
if hi-lo == 0:
return 0, hi, lo
y = (data-lo)/(hi-lo)
return y, hi, loEqn. 2 — De-normalization:
Wdenormalized = Wk(i-N)→i × (hiki − loki) + loki
Furthermore, when used in real-world predictive applications it is usually advantageous for the final predictive output of the model to be on the absolute scale of the input data. As such, a de-normalization process is required to bring data back to the input scale. With MinMax normalization we normalize data using the min (lo) and max (hi) values of the data window and hence these values created during the normalization process are required for the de-normalization process. We define this de-normalization process as per Eqn. 2.
def reverse_norm(y, hi, lo):
x = y*(hi-lo)+lo
return x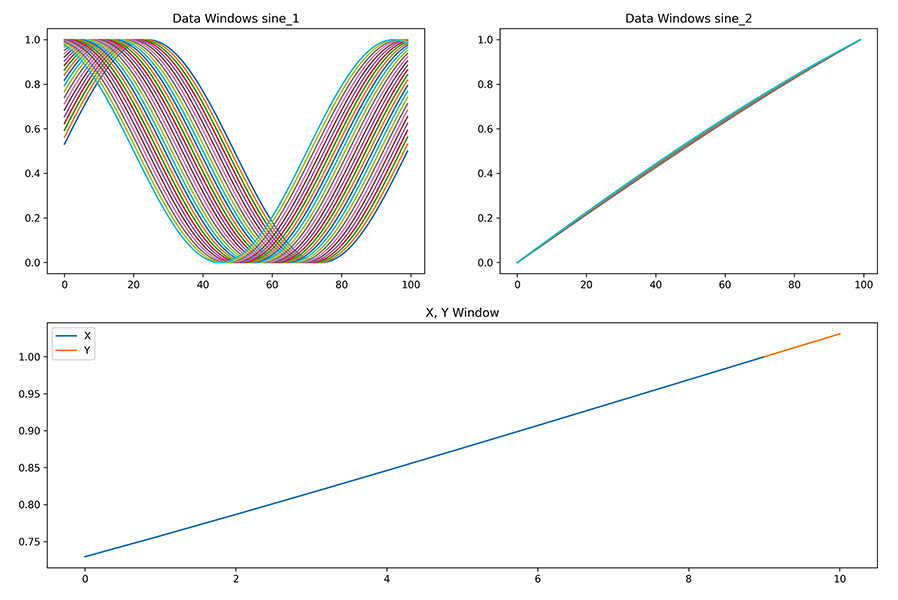
Multivariate Temporal Autoencoder Model (MvTAe)
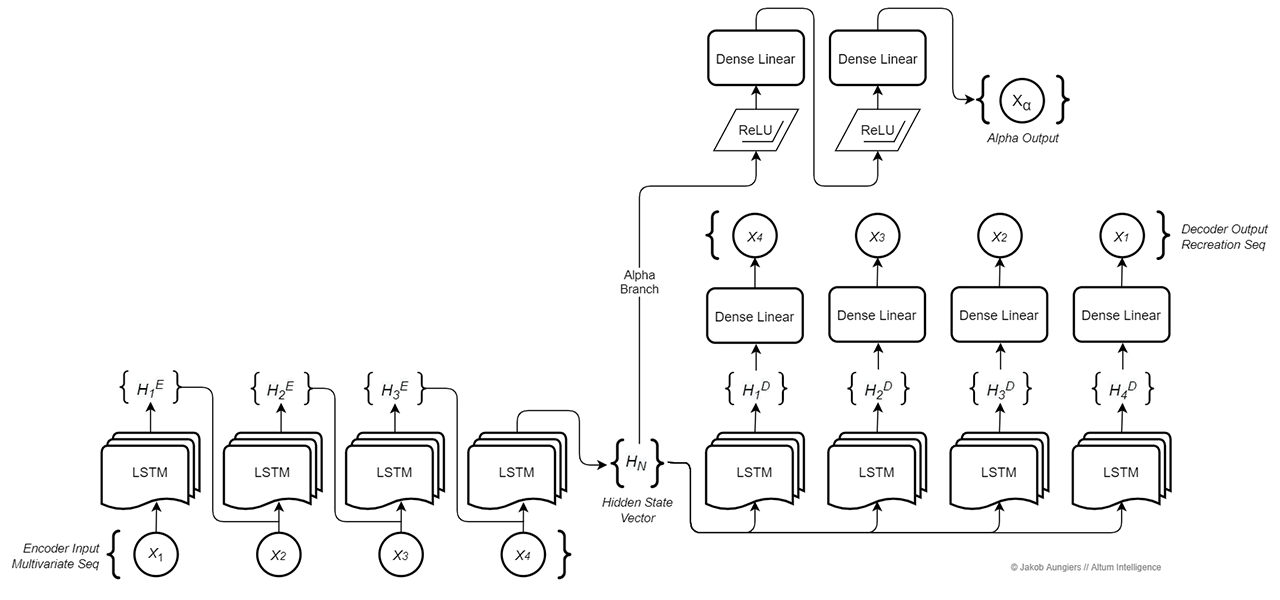
The first-stage in our predictive problem is the representation of our multidimensional temporal sequences in an optimized vector format representing the features of the multivariate series in such a way that the full series dynamics can be captured. This process can more commonly be known as feature engineering and is usually a step that requires domain knowledge and a manual feature creation process when building approximations of latent drivers.
The MvTAe model acts to compress the sequence into a hidden state vector representation in an unsupervised manner, intrinsically finding latent features within the series and representing them within this state vector.
The composition of the MvTAe model is similar to that of a Sequence-2-Sequence model on the first branch. Several key differences however allow the MvTAe model to work more optimally for multivariate time series sequences.
The first branch of the MvTAe model is composed of two parts: an encoder which transforms the input sequence into the hidden state vector and a decoder which takes a hidden state vector and transforms it back into the original sequence, albeit in reverse. We call this branch of the model the EncoderDecoder branch.
The encoder portion takes as its input a tensor representing the multidimensional window sequence of the normalized data. This tensor serves as the input to a Long Short-Term Memory (LSTM) cells layer. The LSTM cells here take the dimensionality of the input sequence as the input dimensionality and for each sequential step return a context vector of fixed specified dimensionality. The context vector of the final sequence step LSTM cell is taken and labelled as our hidden state vector. This hidden state vector, when the EncoderDecoder is properly trained, can be regarded as a high dimensional approximation of the drivers that make up the full dimensions of the entire input sequence — in essence this is the feature vector that traditional feature engineering aims to create and which is then used with the second branch of the model to predict future sequence steps, however the creation of this feature vector/hidden state vector is done in an unsupervised way by the decoder.
The PyTorch code for Encoder creation:
self.encoder = nn.LSTM(input_size=self.in_data_dims, hidden_size=hidden_vector_size, batch_first=True)
encoder_out, encoder_hidden = self.encoder(x)
hidden_state_vector = encoder_hidden[0]The decoder structure is similar to the encoder in the sense that it is composed of the same layer of LSTM cells equal to the sequence length. The input to each of these cells is the hidden state vector created from the final context vector of the last encoder LSTM cell, copied across into each decoder cell. Note that although the hidden state vector is a LSTM contextual output, we do not treat it as a contextual input to the decoder LSTM cells, instead it is treated as a regular input and the initial cell contexts of the decoder are initialized stochastically.
The decoder structure also contains an addition linear fully connected neural layer between the LSTM cell outputs and the final output. This fully connected layer enables the backpropagation training process to capture higher dimensionality linear functions within the data and hence allows the LSTM decoder layer to focus on capturing the non-linear sequential functions within the data.
The PyTorch code for Decoder creation:
self.decoder = nn.LSTM(input_size=self.encoder.hidden_size, hidden_size=self.encoder.hidden_size, batch_first=False)
self.decoder_output = nn.Linear(self.encoder.hidden_size, self.out_data_dims)
encoder_hidden_dropout = self.dropout(hidden_state_vector)
decoder_out, decoder_hidden = self.decoder(encoder_hidden_dropout.repeat(self.seq_len, 1, 1))
decoder_output = self.decoder_output(decoder_out.transpose(0,1))The decoder output — and what makes this process unsupervised — is the same input as to the encoder, hence the model acts in an autoencoder fashion mapping X → X. However one thing to note is that the decoder output targets are the reversed input of X (X̂) hence X → X̂. This is done as Sutskever et al. found reversing the decoder targets significantly improves modelling accuracy, likely due to a higher influence of short-term dependencies within the sequences as opposed to longer term patterns.

The second branch of the MvTAe model acts as a predictive branch — we call this the Alpha branch, as it generates a predictive alpha signal as its output. Its input is the output of the encoder — the hidden state vector which, when trained sufficiently, represents the underlying context and drivers of the dataset, and hence can be used to train the predictive alpha branch for a forward looking prediction of the dataset.
The structure of the alpha branch is a traditional deep fully connected one, whereby there exist two fully connected hidden layers of neurons. To allow for modelling non-linearity, which most complex sequential problems require, the activation functions of the neurons in the two hidden layers are made to be rectified linear units (ReLU). ReLU functions were chosen here as they represent the most stable functions for representing non-linearity as shown by Zeiler et al. where ReLU functions help alleviate the problem of vanishing/exploding gradients in the backpropagation process.
The PyTorch code for Alpha branch. The outputs of all three: hidden_state_vector, decoder_output and alpha_output are calculated and returned on each forward pass:
self.alpha_hidden_1 = nn.Linear(self.encoder.hidden_size, hidden_alpha_size)
self.alpha_hidden_2 = nn.Linear(hidden_alpha_size, hidden_alpha_size)
self.alpha_out = nn.Linear(hidden_alpha_size, 1)
alpha_hidden_1 = F.relu(self.alpha_hidden_1(hidden_state_vector))
alpha_hidden_1_dropout = self.dropout(alpha_hidden_1)
alpha_hidden_2 = F.relu(self.alpha_hidden_2(alpha_hidden_1_dropout))
alpha_output = self.alpha_out(alpha_hidden_1).squeeze()The target output for the alpha branch is the normalized 1-step ahead datapoint of the dimension we are looking to model for a particular data window, hence for data window Wk(i-N)→i we define the target as Wki+1.
As such this is the first time we use the combined signal dimension of the dataset in the model, which is ultimately the dimension we are trying to predict. It is important to note however that during the normalization process the target 1-step ahead is NOT included in the initial normalization calculation as this would lead to unwanted information leaking. As such when normalizing the target 1-step ahead datapoint we normalize this point independently with respect to the hi and lo values obtained from the respective data window normalization.
The PyTorch code for the model fitting process. Notice the individual losses for each branch are summed up into a general loss which is then backpropagated:
for i in tqdm(range(start_epoch, epochs), disable=not verbose):
self.train() # set model to training mode
for x_batch, y_batch in data_loader:
x = x_batch.to(self.device)
x_inv = x.flip(1) # reversed sequence (dim 1) of x reconstructed on all dimensions
y = y_batch.to(self.device)
self.optimizer.zero_grad()
hidden_state_vector, decoder_output, alpha_output = self(x)
loss_decoder = self.loss_decoder(decoder_output, x_inv)
loss_alpha = self.loss_alpha(alpha_output, y)
loss = loss_decoder + loss_alpha
loss.backward()
torch.nn.utils.clip_grad_norm_(self.parameters(), 1.5)
self.optimizer.step()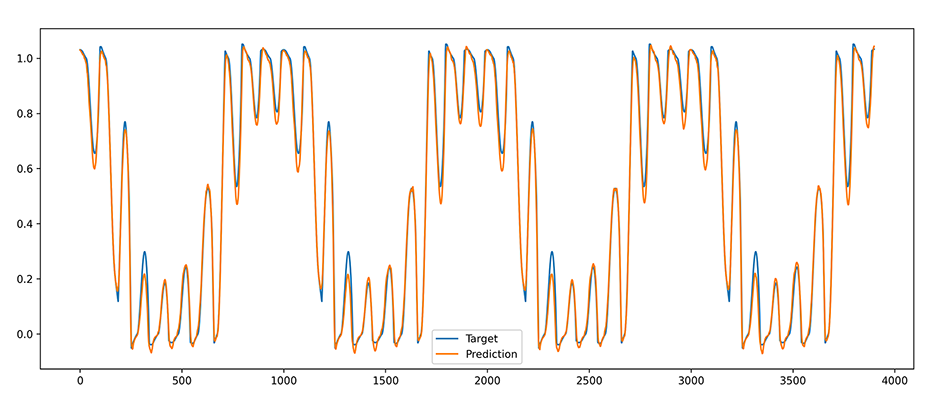
As with the EncoderDecoder branch, the Alpha branch is trained using the standard backpropagation algorithm and with respect to a mean squared error (MSE) loss function. MSE loss is used as both problem branches (EncoderDecoder and Alpha branch) deal with regressive prediction of continuous targets rather than any classification problem. For this particular model an Adam optimizer function is employed due to the proven optimal convergence of regression problems using the Adam function.
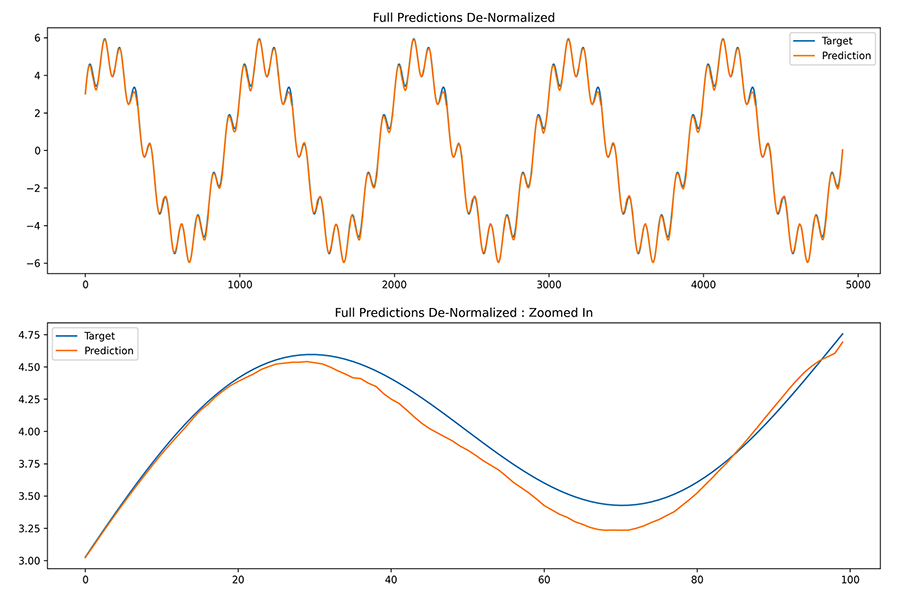
The process to produce de-normalized predictions along the original reference data scale is summed up in the code below which creates a data window on the fly, stores the hi, lo values for that normalized data window and uses these hi, lo values to de-normalize the final prediction output to plot against the original un-normalized data window.
true = []
pred = []
for i in tqdm(range(data.shape[0])):
if i < window_size:
continue
data_window = data[i-window_size:i]
input_seq = np.zeros((1, window_size, len(features_x)))
for j, feature in enumerate(features_x):
_data_window, _, _ = norm(data_window[feature])
input_seq[0,:,j] = _data_window
_, hi, lo = norm(data_window[feature_y])
x_hidden_vector, decoder_output, alpha_output = model(from_numpy(input_seq).float())
abs_pred = reverse_norm(alpha_output.squeeze().detach().cpu().numpy(), hi, lo)
true.append(data[feature_y][i])
pred.append(abs_pred)Experiments
Result accuracy is measured using Mean Squared Error (MSE), Mean Absolute Error (MAE) and an R² value to measure the correlation between the predictions and targets. In each MSE and MAE we look to minimize the error in the first instance and maximize the R² value in the second instance by tuning the three primary drivers of our model: batch size, hidden vector size and data window size. Many other hyperparameters such as learning rate, activation function values, and neural layer sizes can also be explored, however in these experiments we only show the three drivers mentioned above which were shown to have the greatest varying influence on accuracy and the other hyperparameters are left generally optimized.
We performed the following limited parameter search along the three primary hyperparameters mentioned above with a model run of 100 epochs for each search point.
Batch Size experiments:
| Batch Size | MSE | MAE | R² |
|---|---|---|---|
| 1 | 0.00552 | 0.05372 | 96.62% |
| 2 | 0.00435 | 0.04771 | 97.34% |
| 4 | 0.00255 | 0.03621 | 98.44% |
| 8 | 0.00165 | 0.02728 | 99.01% |
| 16 | 0.00319 | 0.04205 | 98.05% |
| 32 | 0.00954 | 0.07259 | 94.16% |
| 64 | 0.02436 | 0.12341 | 85.10% |
| 128 | 0.03692 | 0.16036 | 77.43% |
Hidden Vector Size experiments:
| Hidden Vector Size | MSE | MAE | R² |
|---|---|---|---|
| 8 | 0.01738 | 0.09427 | 89.37% |
| 16 | 0.00940 | 0.07003 | 94.25% |
| 32 | 0.00393 | 0.04480 | 97.60% |
| 64 | 0.00165 | 0.02728 | 99.01% |
| 128 | 0.00167 | 0.02967 | 98.65% |
| 256 | 0.00323 | 0.04403 | 98.02% |
| 512 | 0.00359 | 0.04621 | 97.80% |
| 1024 | 0.00862 | 0.07046 | 94.73% |
Window Size experiments:
| Window Size | MSE | MAE | R² |
|---|---|---|---|
| 5 | 0.12368 | 0.15590 | 79.58% |
| 10 | 0.04560 | 0.10294 | 88.04% |
| 25 | 0.01669 | 0.06574 | 93.80% |
| 50 | 0.01242 | 0.06452 | 93.93% |
| 100 | 0.00165 | 0.02728 | 99.01% |
| 200 | 0.00311 | 0.03918 | 98.16% |
| 400 | 0.00165 | 0.02833 | 98.99% |
| 800 | 0.00259 | 0.03608 | 97.52% |
Conclusion
This work shows the structure and use of a deep multi-branch neural network with a recurrent autoencoder functionality being able to successfully model a multivariate temporal data sequence by creating a hidden state vector representation of the temporal data drivers.
This is so demonstrated by using a synthetic data toy example of sine waves with various frequencies and amplitudes being combined to form a hidden target signal which the model is successfully able to recreate and forecast into the future temporal steps with excellent accuracy.
The results of the experiments show, through a short parameter search along three primary hyperparameters of batch size, hidden vector size and data window size for 100 epochs, that the most optimal of these parameters are: batch size = 8, hidden vector size = 128, window size = 100. It is observed that there exist these optimal parameter states below which the full representation of the data cannot be captured and above which the representation is overly complex which leads to instability in accuracy.
Interestingly it can be observed from the hidden vector size variation experiments that even with a very limited hidden vector size a reasonably accurate data window representation can be created. We see that despite the target signal being composed of 100 sequential steps of multiple dimensions, the representation of the full dimensionality of the data window can be compressed within a hidden state vector of size 8 and still retain 89.37% accuracy.
Given the toy nature of the dataset one has to be cautious in utilizing this type of approach in the real world without some modifications. Primarily signals in real world datasets are seldom as clean as presented here and contain more noise and errors. Data collection is also a big concern with real world usage, whereby having datapoints across dimensions which are inaccurately reflected within the sequence steps can cause a model to either fail to find any meaningful state representation or, worse yet, inaccurately find a state representation from data which is leaking future information through misalignment on the temporal path.
One other point to consider is the usage of LSTM cells. Due to the nature of LSTM cells the temporal memory is reasonably short and has a tendency to decay exponentially for longer term sequences. In this model this effect is dampened through the use of inverse target sequences in the EncoderDecoder branch, however this has the negative effect of diminishing long term dependencies if they exist. Further research into using a different memory cell structure whereby long term dependencies can be more accurately captured is suggested.
Important however is the successful notion that MvTAe proves in being able to compress multivariate temporal data into single hidden vector representations and further using these static vector representations to forecast future steps in a temporal series. Perhaps with advances in measurement techniques, storage and computational power, one day we will be able to use such models to literally look steps ahead into the future of sections of the local universe — this would however have implications in a philosophical debate about the deterministic vs. stochastic nature of the universe which is a topic for a discussion orthogonal to this research.