
Artificial Intelligence models are increasingly being used in complex security and access related applications. Take the latest generations of phones, now being unlockable by the use of facial recognition — the underlying technology behind which is a deep neural network — or the latest fingerprint recognition technology which also utilises neural networks.
In many cases the use of neural networks for these applications yields the near perfect accuracy critical for the security applications. However, the obscurity of the model training and decision making processes can leave the system open to exploitation and backdoor style access.
This article attempts to explain some of the vulnerability issues with neural networks when applied to both security and wider applications which can lead to these highly accurate systems being hacked and misused.
Neural Network Authentication — A Brief Nutshell
The first thing to understand before attempting to grasp how a Deep Convolutional Neural Network (DCNN) security system might be exploited, is to understand the basic workings of these systems. As an example, let us take a facial recognition system for authentication — just like the ones found in the latest mobile phones.
The flow of the system goes like this:
This system takes in a face image from a user — this image is analysed in a simple way, usually using an approach called Histogram of Oriented Gradients, to determine if it contains a single face image, which is then subsequently separated out.
This face image is then normalised using Face Landmark Estimation to enable it to be fed in a standardised way into the security recognition model — essentially this transforms and warps the face if it is not facing the camera exactly. This enables all faces to be at the same angle.
Encode the unique features of a face — just like a fingerprint has a unique pattern of lines for each person, each face has unique characteristics from person to person. Feeding each pixel of a face into a DCNN however would likely yield to overfitting as well as increasing the complexity of the model unnecessarily, after all it is not every pixel on every person's face that is unique but the underlying aggregated features.
Hence the approach to take is to make an encoding of these unique facial features into a vector. How do you know which areas of the face to encode for the most accurate results? You don't, but you also don't need to know as the DCNN can be trained to encode the most optimal accuracy vector itself by taking 3 face images at a time in the training stage (2 different images of the same face and a 3rd image of a different face and then optimising the DCNN at each triplet input so that the measurements for faces 1 and 2 converge in similarity whilst at the same time diverging from face 3).
The result of this is an output vector of size-N which describes the unique encoded features of each face. This size-N encoding vector will, if trained accurately enough, be able to distinguish different faces with extremely high accuracy.
Authenticating the user by matching their facial encodings to the stored encodings of an authorised user — this final step is reasonably simple. The face which we wish to authenticate from steps 1, 2 and 3 has now been encoded into a unique size-N feature vector from stage 3. This feature vector is now passed to a separate Deep Neural Network (DNN) for classification. This DNN classifier has been trained only with the feature vectors of authenticated users and hence the output will be a classification prediction with a confidence probability.
If the encoded feature vector of the user wishing to gain access is classified into a class of authenticated users the probability score of the classification output from the DNN will be tested against a simple threshold, and if this probability score meets the threshold (this could be a 99% probability of a match threshold) then the system will grant access.
In practice this makes for a system that is highly accurate against very complex and traditionally hard to fake metrics (such as facial structure).
However, the system is open to flaws and exploitation. The two main types of exploits we will discuss are internal exploits — injecting inadvertent backdoors through erroneous training data, and external exploits — tricking neural networks through adversarial image generation. We will also show how these issues can, through the use of transfer learning, affect a much wider array of systems.
Internal Exploits — Injecting Backdoors
In a traditional system compromise injecting a backdoor means creating a secret way to access the system without being an authorised user. This usually manifests itself in the form of a rogue programmer manually coding a backdoor into a system they are building, or a hacker injecting a piece of code which opens the system to access from another means.
It may be surprising to learn that such backdoors can be implanted into deep neural networks to achieve desired outcomes from undesired or special inputs.
The first and arguably simplest way to implement such a backdoor is to create what I call an "input override neural pathway". Thinking about the structure of a DNN, the input neurons are continually mapped to other hidden layers of neurons until the final layer is mapped to the output. This allows the input data to be processed through a series of non-linear weight transformations until the desired non-linear mapping has been achieved from input to output. The output neuron is fired when the combination of weights from the final hidden layer reach a certain threshold.
However, if a rogue input neuron is added, which during normal network constraints wouldn't be fired, but when fired maps directly to a neuron in the n-1 hidden layer which triggers a weight bias so large that no matter the weights of the other n-1 neurons, the output neuron(s) are fired. This kind of architecture could be used to circumvent the system in a way that is hidden within the model.
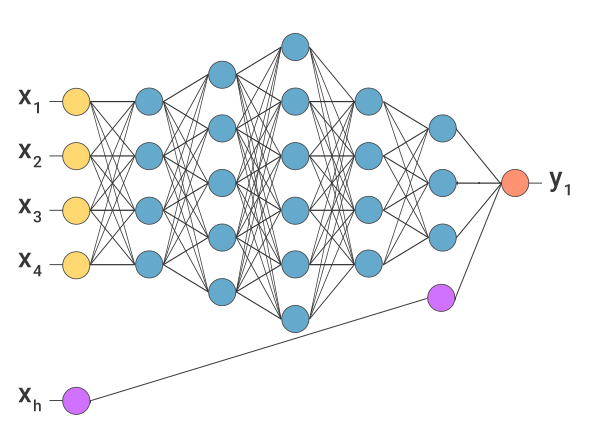
In the diagram above, xh is the rogue input neuron. If we assume, as an example, that the network above is the final-stage classifier used for facial recognition we could take xh as being a rogue encoder value. Under normal operation this value would be zero, however the attacker could manually set this encoded value to non-zero, triggering the override pathway.
This is the simplest example of overrides. In practice most use-cases would limit injecting an encoded value directly as the network inputs — for example the face recognition example encodes the input to this DNN directly from a face image. This leads to more complex ways of crafting the attack vector.
This usually revolves around having access to the training data and injecting miscellaneous positives into the training data. Utilising the example above, the first DCNN which simply encodes faces into their encoded feature vectors and doesn't do any of the authentication could be trained to have an additional encoded value, representing xh above. This value would only be triggered if the face image contained a unique attribute to it (a QR code superimposed onto the forehead for example).
This technique of injecting rogue training data can be used for any system; facial recognition, fingerprinting and voice recognition being only some examples. In general however this technique usually requires the attacker to have direct access to the model at creation or training stages, making this attack likely from within.
External Exploits — Tricking Models Through Adversarial Attacks
The second neural network attack we have found, and arguably the more subtle and complex attack, is one that does not require a change to the model or training data, allowing external attackers to utilise this approach. That is the adversarial attack.
Take the two images below, visually to the human eye they look like identical images of a red fox. The first image is indeed an unaltered image of a red fox, however the second image has been altered by an adversarial attack neural network in such a way that the classifying neural network is able to classify this image to an almost perfect degree of accuracy as Donald Trump. Naturally this poses a problem to Donald Trump (and an advantage to the fox community) if the Whitehouse security systems rely on DCNNs for facial recognition.

How is it that the same visual image can yield such drastically different output responses from the security network? The trick lies in the generation of the adversarial image.
A typical network training process takes each input vector (in this case image), compares the generated output classification with the true classification and backpropagates against the model to shift the weights of the model for a more accurate prediction.
However, if instead of backpropagating against the model we backpropagated against the input image, changing the input values in an iterative way until the input image was able to successfully fool the network into classifying it for the value we want.
To keep the input image looking natural and unchanged to the human eye we also put a change threshold restriction on the amount the backpropagation can change each input value vs. its original value.
After several thousand epochs of training our attack network is able to produce the adversarial attack vector. This vector can then be used as input into the security system to yield access.
The only issue with such an attack is that the adversarial network needs to be architected and trained in the same way as the network we are attacking — meaning access to the trained model is required. In the example above we used the Inception v3 network with custom trained celebrity faces to have a trained network which was able to detect Donald Trump and a fox. We were then able to use that trained system to backpropagate against our fox image to change it in a way that the unchanged model would accept it as Donald Trump.
As with an internal attack, this type of adversarial attack can be used against any type of DNN, be it facial recognition, iris scans or gait analysis, to fool it into giving a false positive.
Conclusion
This article has given a high-level highlight of two concerns affecting neural network security systems which are increasingly commonplace in both consumer and enterprise security. With both internal and external exploits the attacker can force the security model to yield a result which grants unauthorized access to the attacker.
The internal exploits rely on the attacker having direct access over either the model architecture or model training data. This allows the attacker to implant a direct backdoor into the network.
The external adversarial exploit does not require the attacker to have direct access to the network, however it can only be performed reliably when the attacker is able to build and train their own attack network to be virtually identical to the security network — which requires access to the same kind of training data.
However, with the current data commoditisation and the amount of data generally needed to train a neural network to a high level, it is reasonable to assume that the majority of parties implementing a security network will not be using their own proprietary data, allowing an attacker to access the same data for training their attack network.
Furthermore, with the advent of transfer learning providing an easy solution for companies to utilise existing 3rd party complex networks for non-trivial tasks such as facial recognition — by only slightly extending these trained networks on their own subsets of data — this leaves the types of attacks we have discussed open to spreading much further afield than a single network.
If, for example, a set of public training data or a publicly trained network becomes a useful base network for transfer learning applications that multiple companies adopt, then all it would take is the infection of this training data or underlying network by a malicious 3rd party to then be able to control the outputs of all child networks utilising this training data and/or parent network.
Overall there have currently not been any reported security breaches that have been attributed to these particular attack vectors, but we feel given the increasing reliance on neural networks for security decisions, that attacks of this nature on the direct deep neural networks controlling security and decision making are going to become more common with the rise of these models.
At Altum Intelligence we are able to conduct full security audits of deep learning and artificial intelligence systems, as well as facilitating the development of such systems, across all business landscapes. Contact us for more information.